VLOOKUP Quirks
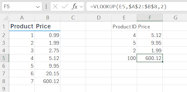
What happens when you give VLOOKUP something it can't find? It is supposed to return #N/A. That is true when you tell it to do full matches on the value you are looking up. But what is the default behaviour?
What happens when you give VLOOKUP something it can't find? It is supposed to return #N/A. That is true when you tell it to do full matches on the value you are looking up. But what is the default behaviour?

A comparison between Microsoft Copilot and Google Gemini Pro for generating an Ansible playbook to install Nagios.

I am happy to report that I met my 2022 goal to read more fiction this year. After a slow start to 2023, I managed a reasonable year including a couple of large tomes I've had on my list for a long time.

I have been logging the books I have read for ten years. This post will summarise what I've been reading and how that has changed over the last ten years.
My reflections on nearly 20 years with OPENXTRA Limited a Value Added Reseller I co-founded all the way back in early 2003.

Thankfully COVID-19 hasn't intruded too much into 2022 but I've still managed an above average reading year. I read a total of 15 books during 2022. Of the 15 books read during 2022, 11 were non-fiction. My goal for 2023 is to read more fiction.
It is a testament to how far consumer electronics has come in the last 15 years that I don't get pestered any more about fixing PCs.
A simple Python script for converting Hugo posts into post bundles to make your posts appear in alphabetical order and therefore speed code navigation.
You have a one off task you need to do. There's an automated process you can build to achieve the end result or you could do the process manually. How do you decide which route to go down?
Another strange COVID-19 affected year, another above average reading year. I read a total of 12 books during 2021. Of the 12 books, 8 were non-fiction. Seems to be a bit of a trend I've noticed.